02. [Keras Lab准备] 录取学生
迷你项目之 Keras Lab 准备: 录取学生
现在我们准备分析 Keras 上的整个数据集。我们将分析以下加州大学洛杉矶分校的学生录取数据集:
'http://www.ats.ucla.edu/stat/data/binary.csv'
在本课的学习过程中,我们鼓励你在页面末尾参考 Jupyter Notebook。我们将为你提供一个解决方案,但请尝试创建自己的深度学习模型!这种体验的价值很大程度上在于,用你自己的方式玩转代码。
克隆 repo 并打开 Notebook(可选)
Notebook 将在教室内打开。但是,如果你想单独打开它,可以通过在终端中执行以下命令,从GitHub存储库中克隆这些资料:
git clone https://github.com/udacity/aind2-dl.git.
按照仓库中的说明设置 Conda 环境并安装必要的依赖项。
(注:如果配置后,打开jupyter notebook运行ipy文件时,kernel启动不起来,并出现以下错误
KernelRestarter: restarting kernel (2/5)
/Users/LeiWang/.pyenv/versions/anaconda3-5.0.1/envs/aind-dl/bin/python: No module named ipykernel_launcher
如果出现这个错误:terminal中再输入ipython3 kernel install 方可正常运行)
在本实验中,导航到主分支,然后打开** Student_Admissions.ipynb **。
研究数据
数据集包含以下列:
- 学生 GPA(成绩)
- GRE 考试成绩(考试)
- 级别(1-4)
首先,我们来看看数据。为此,我们将在 pandas 中使用 read_csv 函数。
import pandas as pd
data = pd.read_csv('http://www.ats.ucla.edu/stat/data/binary.csv')
print(data)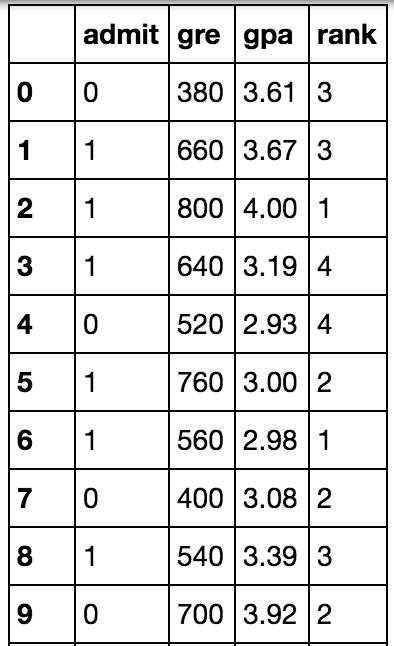
在这里我们可以看到第一列是标签 y,它对应于接受/拒绝。 即标签 1 表示学生被录取,标签 0 表示学生不被录取。
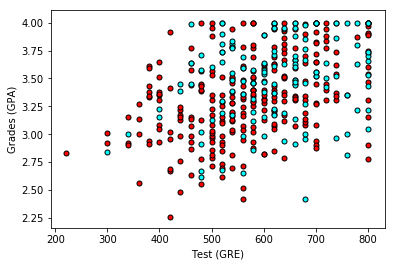
当我们绘制数据时,会得到如下图表,不幸的是,数据并不像我们希望的那么整洁得一目了然:
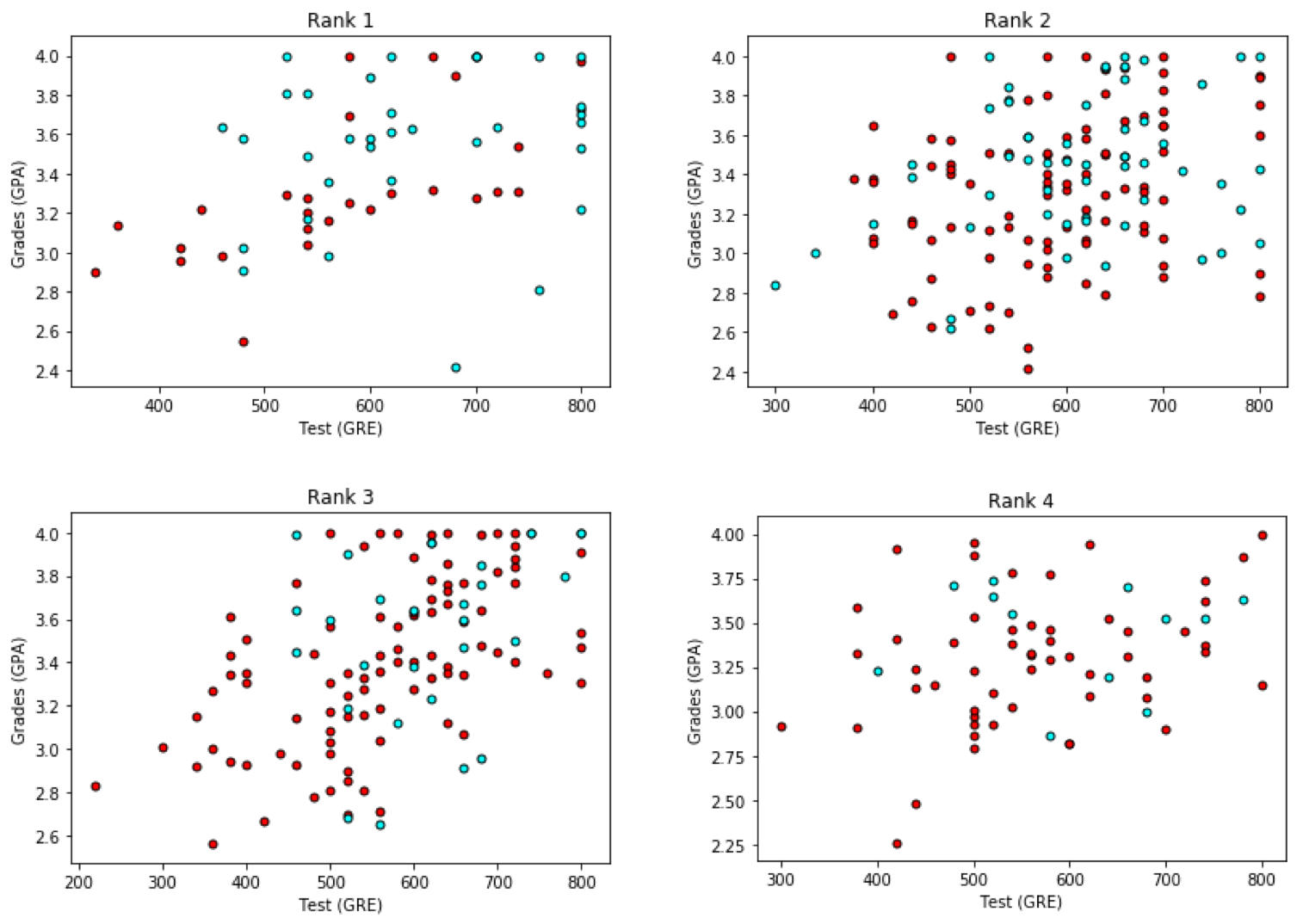
接下来,我们可以做的一件事就是为每等级制作一张图,共四张图。 在这种情况下,我们得到这个:
预处理数据
从这里,我们看到更多的希望。 因为看起来的情况是学生的考试成绩越好,他们越有可能被录取。 等级与此有关。 所以我们要做的是,对排名等级进行一次性编码,我们的6个输入变量是:
- 考试 (GPA)
- 成绩 (GRE)
- 等级 1
- 等级 2
- 等级 3
- 等级 4.
最后4个输入将是二进制变量,如果学生具有该等级,则其值为1,否则为0。
首先要注意的是,考试分数的范围是800,而成绩范围是4,这是一个巨大的差异,这会影响我们的训练。 通常情况下,最好的办法是将分数归一化,使其在0和1之间。我们可以这样做:
data["gre"] = data["gre"]/800
data["gpa"] = data["gpa"]/4现在,我们将数据输入分成 X和标签 y,并对输出进行 one-hot 编码,因此它显示为两类(录取和不录取)。
X = np.array(data)[:,1:]
y = np_utils.to_categorical(np.array(data["admit"]))构建模型架构
最后,我们定义模型架构。 我们可以使用不同的架构,不过这里有一个例子:
model = Sequential()
model.add(Dense(128, input_dim=6))
model.add(Activation('sigmoid'))
model.add(Dense(32))
model.add(Activation('sigmoid'))
model.add(Dense(2))
model.add(Activation('sigmoid'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()categorical_crossentropy 会给出错误函数,我们一直在使用,但还有其他选项。 有几个优化器可供你选择,以改善你的训练。 在这里我们会使用adam,但像rmsprop也很有用。 它们使用了我们在下面的课程中即将介绍的各种技巧。
模型总结将告诉我们以下内容:

训练模型
现在,我们用 1000 个 epho 训练模型。 不用担心遇到batch_size,我们很快就会学到它。
model.fit(X_train,y_train,epochs = 1000,batch_size = 100,verbose = 0)
评估模型
最后,我们可以评估我们的模型。
score = model.evaluate(X_train,y_train)
结果可能会有所不同,但你应该可以获得超过70%的准确度。
现在,你已经训练了你的第一个神经网络来分析一个数据集。 在接下来的节点中,你将学习许多技巧来改进训练过程。